Groq
Ultra-fast LLM inference on custom LPU hardware
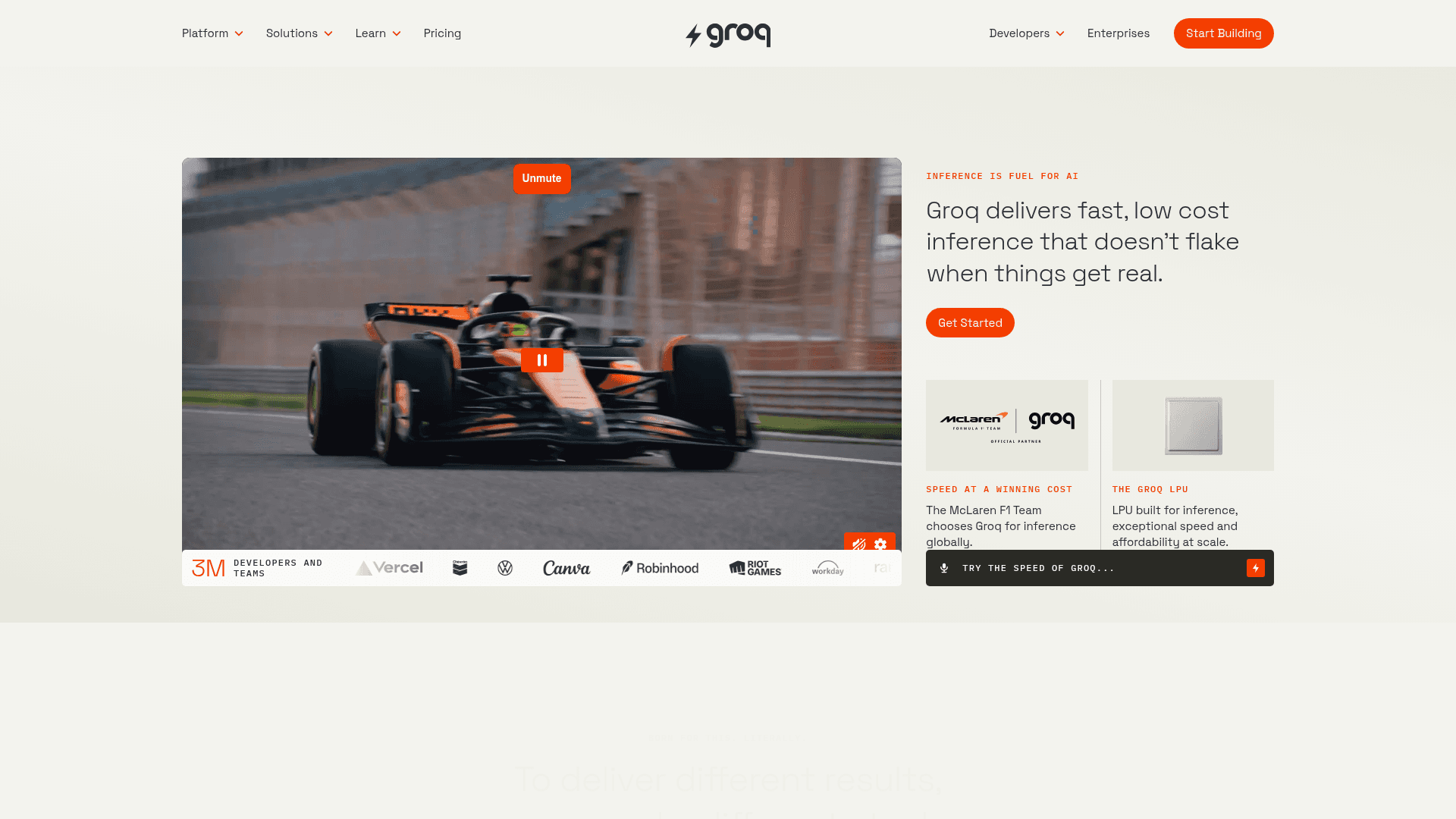
Shyft Score
Directory quality rating
98/100
Quiet
Our take
The verdict on Groq
AI-generated
Groq's custom LPU hardware delivers unmatched LLM inference speeds, making it ideal for performance-critical AI applications. Its support for open-source models via API adds flexibility.
Strengths
- Fastest LLM inference speeds
- Supports open-source models via API
- Free tier available
- Scalable architecture
- Comprehensive documentation
Limitations
- Pricing unclear (contact sales)
- Limited to inference, no training capabilities
- Small ecosystem
Best for: Engineering teams at large enterprises needing high-performance LLM inference
Try Groq's free tier to see if it fits your workflow.
See how Groq fits your stackBenefits
Why teams choose Groq
Accelerate AI model deployment with industry-leading inference speeds
Reduce operational costs with optimized hardware performance
Access open-source models via API for rapid integration
Scale AI infrastructure seamlessly to meet enterprise demands
Minimize development time with comprehensive documentation
About
What is Groq?
Delivers ultra-fast LLM inference through custom LPU hardware, enabling developers to run open-source models like Llama and Mixtral at unprecedented speeds. Built for applications requiring rapid AI responses at scale.
Key capabilities
Custom LPU hardware for optimized performance
Supports open-source models via API
Fastest LLM inference speeds in the industry
Scalable architecture for enterprise needs
Comprehensive documentation for developers
At a glance
Category
ai-infrastructure
Department
Engineering
Pricing
Usage (from $0.05 per million input tokens (Llama 3.1 8B Instant))
Website
groq.com
Capabilities
MCP
Use cases
What you can do with Groq
Build real-time AI applications requiring sub-second response times
Deploy high-throughput inference for chatbots and content generation
Run complex reasoning tasks at competitive pricing with ultra-low latency
Best for
AI researchersEnterprise AI developersData scientists
Pricing
Groq pricing
Groq starts at $0.05 per million input tokens (Llama 3.1 8B Instant)
Starting at $0.05 per million input tokens (Llama 3.1 8B Instant)
Pricing and product details are aggregated from publicly available sources, may be outdated or inaccurate, and are not sourced from or endorsed by the vendor. Verify directly with the vendor before relying on this information. Terms
Ecosystem
Connected ecosystem
MCP servers, AI skills, and integrations that work with Groq
MCP servers
Use Groq with AI agents via these MCP servers
multimodal agents course
Build advanced AI agents that understand and process multimodal data.
pip 554
MakerAi
The AI Operating System for Delphi, enabling intelligent applications with advanced AI models.
159
NextChat
NextChat: Your lightweight AI assistant for seamless multi-platform interactions.
npx 87.8k
observee
Build AI agents effortlessly with 1000+ integrations and managed OAuth using Observee.
npx 42
witsy
Witsy: Your universal AI assistant for seamless integration with multiple LLMs.
npx0
Integrations
AI & automation capabilities
REST APIN/A
MCP Server
WebhooksN/A
Free Tier
Reviews
What users say about Groq
Ratings from verified review platforms
Connected integrations
9+
9
FAQs
Frequently asked questions
Common questions about Groq and its capabilities
Groq is an AI infrastructure platform that provides ultra-fast LLM inference using custom Language Processing Unit (LPU) hardware. It offers API access to open-source models with industry-leading speed and scalable architecture designed for enterprise AI applications.
Need help automating Groq?
Our team can help you integrate Groq with your existing tools and build custom automation workflows.
No commitment requiredResponse within 24h
Get weekly AI tool updates
Pulse delivers engineering-specific AI insights every week. Free.
Explore
Discover more
Alternatives, related tools, and resources for Groq
Related Resources
Explore Alternatives
Browse by Category
Related Tools
Using Groq? See how your stack compares.
Our free scan analyzes your website, detects your tools, and shows gaps in your AI readiness.
Take free scan →